텍스트 및 문자 찾기
텍스트 유형의 필드 또는 텍스트 결과를 반환하는 계산 필드의 텍스트를 검색할 수 있습니다.
텍스트 및 문자 찾기:
-
찾기 요청을 시작합니다.
찾기 요청 만들기를 참조하십시오.
찾기
필드에 값 입력
예제
특정 로마 문자로 시작하는 단어(일본어를 제외한 모든 언어를 사용하는 필드와 함께 동작)
문자
Chris Smith는 Chris Smith, Smith Chris, Chris Smithson 및 Smith Christenson을 찾습니다.일본어 히라가나, 가타카나 또는 간지 문자로 시작하는 단어
=과*사이의 문자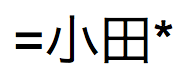 는
는  ,
,  및
및  를 찾습니다.
를 찾습니다.단어의 첫 번째 문자일 때 일치하는 구문 또는 문자 시퀀스(단어 시작에서 구문 일치)
공백과 문장 부호를 포함하여, 따옴표(
") 사이의 리터럴 텍스트(문자)"Marten and Jones Interiors"는 Jones and Marten Interiors가 아니라 Marten and Jones Interiors를 찾습니다."
, Ltd."는 이름에 ", Ltd."가 있는 모든 회사를 찾습니다. 쉼표가 없으면 찾지 않습니다."Spring"은 ColdSpring Harbor나 HotSpring이 아닌 Springville을 찾습니다.하나 이상의 알 수 없는 또는 변수 문자(임의의 한 문자)가 있는 단어
각각의 알 수 없는 문자에 대해 하나의 와일드카드 문자(
@)Gr@y는 Gray와 Grey를 찾습니다.@on은 Bron이 아닌 Don과 Ron을 찾습니다.텍스트 필드의 유효하지 않은 문자
?유효하지 않는 문자는 빈 문자로 표시합니다.
참고 ? 문자를 찾으려면
"?"를 검색하십시오.텍스트 필드의 숫자(임의의 한 자리수)
각 자리수에 대한
#문자#은 30이 아닌3을 찾습니다.##은 3이나 300이 아닌 30을 찾습니다.#3은 3이 아닌 53과 43을 찾습니다.0 이상의 알 수 없는 또는 변수 텍스트 문자가 연속으로 있는 단어(0 이상의 문자)
알 수 없는 모든 문자에 대해
*Jo*n은 Jon과 John을 찾습니다.J*r은 Jr.와 Junior를 찾습니다.*phan*은 Phan과 Stephanie를 찾습니다.S*은 Sophie, Steve와 Sven을 찾습니다.문장 부호나 공백과 같은 연산자 또는 기타 비-영숫자 문자
공백과 문장 부호를 포함하여, 따옴표(
") 사이의 리터럴 텍스트(문자)"@"는 @(또는 예를 들어, 이메일 주소)를 찾습니다.","는 쉼표를 포함하는 레코드를 찾습니다." "는 연속으로 세 개의 공백을 찾습니다.FileMaker Pro가 인식하는 공백 문자 또는 찾기 연산자와 같이 특별한 의미가 있는 문자:
@, *, #, ?, !, =, <, >, " (escape 다음 문자)
\뒤에 특수 문자가 따라옴탐색 모드에서 캐리지 리턴의 경우 필드에 캐리지 리턴을 입력하고 이를 클립보드로 복사합니다. 그런 다음 찾기 모드에서
\를 입력하고 캐리지 리턴을 붙입니다.탭의 경우
\를 입력한 다음 Ctrl+Tab(Windows) 또는 Option-Tab(macOS)을 누릅니다.\"Joey\"는 "Joey"를 찾습니다.joey\@abc.net는 이메일 주소 joey@abc.net을 찾습니다.\는 Joey를 찾습니다.
캐리지 리턴으로 Joey악센트 부호가 있는 문자가 있는 단어
공백과 문장 부호를 포함하여, 따옴표(
") 사이의 리터럴 텍스트(문자)"òpera"는 opera가 아닌 òpera를 찾습니다(따옴표가 없는
òpera는 òpera와 opera 모두를 찾습니다).일부 구문, 단어 또는 문자 시퀀스(모든 곳에서 구문 일치)
따옴표( ) 사이의 문자, 문장 부호 및 공백. (
"); 인용된 텍스트 앞에*을 배치하면 필드 내 어느 부분이든 일치할 수 있고, 뒤에*을 배치하면 구절이 단어 중간에 끝날 수도 있습니다(주석 참조).*"son & Phil"*은 Johnson & Phillips와 Paulson & Philson을 찾습니다*"son & Phillips"는 Johnson & Phillips와 Paulson & Phillips를 찾지만 Paulson & Philson은 찾지 못합니다.지정한 텍스트와 정확히 일치(전체 필드 일치)
내용이 일치하는 필드에 대해
==(두 개의 등호)==John은 John Smith가 아닌 John을 찾습니다.==John Smith는 Smith, John이나 John Smithers가 아닌 John Smith를 찾습니다.지정한 전체 단어와 정확히 일치(전체 단어 일치)
==Market은 Marketing이나 Supermarket이 아닌 Market, Market Services와 Ongoing Market Research를 찾습니다.=Chris =Smith는 Chris나 Christopher Smithson이 아닌 Chris Smith나 Smith Chris를 찾습니다.일본어 히라가나, 가타카나 및 간지 문자를 포함하는 단어(일본어로 인덱스된 필드 전용)
문자
 는
는  ,
,  및
및  를 찾습니다.
를 찾습니다.히라가나/가타카나, 탁음/반탁음/무성음 가나, 작은/일반 가나 및 가나 유성음/무성음 반복 표시 간에 구분 없이 일본어로 인덱스된 필드의 가나 문자
융통성 있는 검색을 위한
~(틸드) 및 문자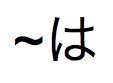 는
는  ,
, 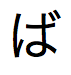 ,
, 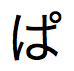 ,
, 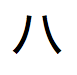 ,
, 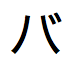 및
및 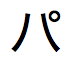 를 찾습니다.
를 찾습니다. -
상태 툴바에서 찾기 수행을 클릭합니다.
참고
-
일반적으로 찾기는 대/소문자를 구분하거나 전각/반각을 구분하지 않습니다. 예를 들어 일본어 반너비 문자를 포함하는 찾기 요청은 동일한 전체 너비 문자를 포함하는 결과와 일치합니다.
기본 인덱스를 변경하고 유니코드로 필드의 언어를 정렬하여 필드에서 대/소문자를 구분하고 전각/반각을 구분하여 찾기를 수행할 수 있습니다. 하지만 이 절차는 필드가 정렬하는 순서를 변경합니다. 원본 필드를 유니코드 순서로 정렬하기를 원하지 않는 경우, 공식은 간단히 대/소문자 구분이나 전각/반각 구분 찾기를 수행하고자 하는 필드인 계산 필드를 생성하여, 기본 인덱스와 이 필드의 정렬 언어를 유니코드로 변경합니다. 그런 다음 필드 중 하나를 정렬하고 다른 하나에 대해 찾기 요청을 수행할 수 있습니다. 필드 인덱싱 옵션 정의하기 및 계산 필드 정의하기를 참조하십시오.
-
인용 구에 앞에
*가 있는 경우, 닫는"뒤에*을 추가하지 않는 한 해당 구절은 여전히 단어 경계에서 끝나야 합니다. 예를 들어,*"Phil"은 Phillips를 찾지 못하지만,*"Phil"*은 찾을 수 있습니다.